
基于点评类SNS的城市规划实施结果定量评价研究
1. 引言 城市发展是城市居民在规划引导下的动态时空行为,受工商业布局、自然环境和经济社会等因素影响,城市发展的结果与城市规划的目标通常并不一致。因此,城市管理部门需要了解特定区域在规划实施后的时空变化趋势,即对规划实施结果进行定量评价,...
- 作者:蒋波涛来源:2014测绘学|2015年01月04日
城市发展是城市居民在规划引导下的动态时空行为,受工商业布局、自然环境和经济社会等因素影响,城市发展的结果与城市规划的目标通常并不一致。因此,城市管理部门需要了解特定区域在规划实施后的时空变化趋势,即对规划实施结果进行定量评价,以此检讨前一轮规划实施方案及成果合理性,并为新一轮规划提供时空变化依据[1, 2]。
规划实施结果定量评价的传统方法是选取一组数值指标来量化实施成果,规划部门一般采用重点走访、公开问卷及网络调查等方式来获得规划区域中的评价数据[3, 4],然后运用如投入-产出分析法(cost-benefit analysis)[5]、规划平衡表(planning balance sheet)[6]、目标达成矩阵(goals achievement matrix)和PPIP评价模型(policy-plan/program-implementation process)[7, 8]等工具进行分析。但传统调查方式往往存在有效回复率低、调查样本量不足、样本时效性差及分布不均匀等问题,影响评价的可靠性[9, 10]。
人类正进入“大数据”时代,大数据使得社会信息传播和活动方式发生了重大改变[11],如Facebook、Twitter、微博(Microblog)和点评(类Yelp [12])等社交网络服务(Social Network Service,SNS)[13]应用被称为“社会传感器(Social Sensor)” [14, 15],它们每天能够在互联网上产生海量的、涉及社交用户日常生活层面的数据,扩展了社会信息生产及获取的深度与广度。
针对社交数据的海量、实时及真实特征,本文提出了一种基于点评类SNS数据的城市规划实施结果定量评价方法,它在获取特定评价区域内服务设施点评信息基础上,根据点评信息的潜在语义差异实现了基于文本主题的分类与数值化评分,为定量化城市规划评价提供可靠的依据依据。
2.实验数据
本文以目前国内最流行的点评类SNS服务商“大众点评网(dianping.com)”作为城市规划实施结果评价数据源。“大众点评网”提供覆盖了数百家城市的600余万商户(服务设施)的2800余万条点评信息,其信息不仅具有以自然语言描述的文本,还包含了点评时间、设施位置、评价星级(仅部分点评文本具有、可分为“很差、比较差、一般、好、很好”5种类型)等属性,这些特征能便于规划人员了解特定评价区域中各类型设施的满意度在时间及空间维度上的变化。
本文选择总面积31.3平方千米为北京大上地区域(中关村软件城)为试验区,它是北京市软件与信息产业聚集地,具备完整的服务设施及服务评价信息。由于历史原因,大上地区域目前产业发展参差不齐、新旧社区混杂,生活环境品质差别较大,即将面临新一轮规划。为确保新规划的可持续性,规划师须对已有生活及商业服务设施现状进行充分评估,了解公众对此区域不同服务设施的满意度及变化情况。本文从此区域的2357个服务设施中获得了38320条点评信息,时间跨度从2004年5月至2013年12月,如表 8所示。
Tbl.1 The comments’ form and amount in area of Dashangdi
|
POI类型 |
婚庆 |
酒店 |
美容美发 |
美食 |
亲子服务 |
汽车服务 |
商业设施 |
生活设施 |
休闲设施 |
运动设施 |
|
POI数量 |
51 |
53 |
205 |
884 |
76 |
120 |
295 |
446 |
139 |
88 |
|
点评数量 |
3672 |
578 |
1030 |
27283 |
215 |
215 |
1514 |
1039 |
2344 |
430 |
3.基于LSI的点评文档评分处理
本文提出了一种使用LSI(Latent Semantic Indexing,潜在语义索引)[16]将自然语言描述的评价内容转化为对应分值的评分方法,其过程包括:①提取点评文档中的特征项(关键词汇);②建构对应的“文档-特征项”模型(数学上表达为矩阵);③根据点评文档蕴含的潜在语义对“文档-特征项”模型进行概念分类,获得“文档-主题-特征项”矩阵;④根据文档主题与特征项的映射关系计算每篇点评文档的实际分类,并根据分类为文档赋予对应分值。
LSI是一种被广泛应用于信息检索领域的基于潜概念索引的自然语言统计模型。文档(document)、特征项(term)和主题(topic)是LSA的3个基本概念,其中:①文档d是指文档库D中的一篇独立文本,即D={d1,d2,…,dn},本文每条点评都被视为一篇文档;②每篇文档d由一个或多个特征性t组成,即d={t1,t2,…,tn},在点评数据中特征项就是构成文本的词汇;③每篇文档会表达一个或多个主题c,主题由其相关的共现词汇来表达,即d={c1,c2,…cn}且ci={ti1,ti2,..,tim}(m≤n),本文主要关注用户对点评对象的“满意度”这一个主题。
自然语言描述中对“满意度”的形容是异常复杂的,我们根据自然语言文本的特征及满意度分类构造了一个对应的评价词汇表并将它作为分词的自定义词典,如表 9所示。
Tbl.2 Different words in various degrees of satisfaction
|
分值 |
满意度表达词汇 |
|
5 |
很多、非常多、特别多、挺多的、非常好、特别好、很不错、下次还来… |
|
4 |
多、好、不错、满意、挺好、物有所值… |
|
3 |
还行、马马虎虎、一般、还可以、还凑合、满意… |
|
2 |
比较少、不太多、比较远、不太方便、不方便、不好、不怎么样… |
|
1 |
很少、太少了、太不方便、很不方便、太远、很远、再不来了… |
3.1点评特征项提取
“大众点评”中的文档多以中文语言表达,与英文以单词间空格区分基本语素不同,中文需要通过分词方式将一段文本中的独立词汇提取出来。不同类型特征项对文档主题分类影响很大,由于本文主要关注“满意度”,因此特征性将多选择表示情感的动词、副词和形容词,同时也会包含主要的描述性名词。
基于表 9中不同分值的满意度词汇,对获取的点评文档使用MMSEG软件[17]进行分词提取,表 10中展示了4篇点评文档及其分词结果。可以看出,如果没有表 9作为自定义词典,“很喜欢”这一类复合词汇便会被分解为“很”和“喜欢”两部分,无法体现“满意度”的程度。
Tbl.3 Results of comment documents by segmenting
|
编号 |
点评文档 |
文档分词结果 |
|
1 |
很喜欢的一家店,味道比较纯正,服务也不错。喜欢面食的朋友可以尝试一下绝对会爱上。 |
很喜欢(adj)、比较纯正(adj)、也不错(adj)、喜欢(verb)、尝试(verb)、绝对会(adv)、爱上(verb) |
|
2 |
味道很好!上次鸡肉很咸,不好吃!这次跟服务员说做淡点就非常好吃了!肉夹馍很好吃,下次还来! |
味道(noun)、很好(adj)、很咸(adj)、不好吃(adj)、非常好吃(adj)、很好吃(adj)、下次还来(verb) |
|
3 |
午饭换到这了,这里发挥还算稳定。一般。 |
发挥(verb)、还稳定(adj)、一般(adj) |
|
4 |
好吃的臊子面。很喜欢。 |
好吃的(adj)、很喜欢(adj) |
通过特征项提取处理,从中38320篇点评文档中共提取出517个特征项及两者的映射关系。
3.2构建“文档-特征项”矩阵
我们将点评文档集及其文档对应的特征项以矩阵形式来形式化表达,建构一个秩为38320×517的“文档-特征项”矩阵D,图 23展示了该矩阵的部分数据。
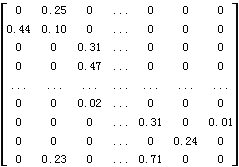
图 23 评价文档的“文档-特征项”矩阵(TF-IDF权重)
其中:矩阵中每行代表一篇点评文档,而每列则代表一个特征项。矩阵值为表示某篇文档中某个特征项重要程度的权重值,本文选择了TF-IDF(Term Frequency–Inverse Document Frequency,特征项频率-逆向文档频率)权重[18]。TF-IDF权重不以特征项出现的次数为重要与否的标准,而是全面考察特征项在点评文档库中的出现情况,如果某个特征项在某篇文档中出现的次数多且在其它文档中出现的次数较少,则认为该特征项能够更好区分文档库中的点评文档且具有较高的权重。
3.3. 满意度主题提取
满意度主题是点评内容中对服务设施满意度高低的评价,它通过一个或多个衡量满意度程度的特征项来表示。以表 10中的点评文档为例,不同用户在4篇评价中使用了“很喜欢”、“下次还来”和“一般”等词汇,这使得文档表达对餐厅的满意程度有所差异,如1、2和4号文档比3号文档更满意餐厅的服务。
满意度主题提取过程包括两部分:①将“文档-特征项”矩阵引入“主题”向量,并通过矩阵分解转化为“文档-主题-特征项”矩阵;②将“主题”向量进行截断处理,将文档的高维主题表示投影至低维潜在语义空间中,从而呈现出潜在的语义结构并再现主题间的差异和关联。
对点评数据的“文档-特征项”矩阵A,我们使用矩阵分解中的奇异值分解方法进行处理后可成为三个矩阵的乘积,如图 24所示。其中38320×38320阶矩阵U表示点评文档,每行向量在LSI中被视为一篇文档; 38320×38320阶矩阵S表示主题,它与U中的行向量逐行对应; 38320×517阶矩阵VT表示特征项,其中每行向量代表了一篇文档包含的特征项。

在矩阵分解中,38320篇点评文档组成的文档库的主题向量是一个38320×38320阶矩阵,即每篇文档都有自己的主题类型。但我们已知点评文档的“满意度”仅有“很差、比较差、一般、好、很好”5种,即需将38320个主题聚集到5个主题中去。由于文档语义的复杂性,将上万条文本仅分为5类会出现许多错误与遗漏,而相关实验证明,相对较小的k值(100~300)可取得有效效果[16],因此本文选择了100作为主题数量,其计算次数小且分类效果显著。
将S从38320×38320阶映射为100×100阶本质上是保留向量S中主要信息的过程,S’是一个值递减的对角矩阵,因此截取其前100项即可。主题缩减后的U’为38320×100阶,S’为100×100阶,而VT’则为100×517阶,它们均是矩阵分解后的矩阵上进行截取而获得的,如图 25所示。

从图 25可知,缩减后生成的S’与VT’两个矩阵为一一映射关系,即VT’中每行向量对应S’中对角线值表示的主题。我们可将此映射表示为一个“主题-特征项”线性映射S’=VT’,其中VT’从矩阵形式转化为“特征项×权重”方程,且特征项次序按权重值高低排列,其结果如表 11所示,它展示了哪些特征项组合在一起时能够构成哪一类主题。
|
Topic1(2.01): -0.332*"味道" + -0.279*"羊肉" + -0.276*"有点" + -0.272*"喜欢" + -0.272*"油泼面" + -0.262*"米皮" + -0.249*"价格" + -0.223*"还可以" + -0.218*"不错" + -0.212*"一般"+… Topic2(1.99): -0.601*"餐厅" + -0.601*"垃圾" + -0.465*"不地道" + -0.213*"陕西" + -0.057*"时候" + 0.044*"很喜欢" + 0.042*"有点" + -0.040*"环境" + 0.039*"喜欢" + -0.031*"还行"+… Topic3(1.87): 0.427*"很喜欢" + -0.381*"不贵" + -0.378*"价格" + 0.349*"喜欢" + 0.334*"有点" + 0.263*"还可以" + -0.190*"羊肉" + -0.188*"时候" + -0.151*"不错" + -0.150*"一般"+… Topic4(1.81): 0.708*"很喜欢" + 0.359*"也不错" + -0.350*"有点" + 0.214*"价格" + -0.187*"还可以" + 0.164*"不贵" + -0.144*"样子" + -0.144*"不好" + -0.115*"服务员" + 0.111*"一般"+… Topic5(1.80): -0.388*"时候" + 0.377*"不贵" + -0.362*"陕西" + -0.314*"环境" + 0.301*"价格" + -0.263*"还行" + 0.253*"肉夹馍" + 0.201*"有点" + 0.178*"服务员" + 0.171*"餐厅"+… …… |
3.4. 商业和公共设施评价值计算
将一篇文档分类至某个主题在本质上是要建立“文档-主题”映射,但由于文档可表示为其特征项集合,因此计算可基于表 11中映射来实现。即将一篇文档的特征项作自变量代入100个主题中,主题值越大说明文档特征项与该主题的特征性越吻合,属于该主题的可能性越高。
将38320篇点评文档通过这样的方式分为100个主题后,剩下的工作则是通过人工判读的方式来将这100个主题归于“很差、比较差、一般、好、很好”5种类型之中。对人使用自然语言撰写的文档,人工判读能准确地了解它要表达的内容。我们只需从100类中挑选2~3条文档即可判断该类主题表示的满意度程度,从而准确地将其归于5类中的某一项。
被分至5大“满意度”主题类型中的文本将根据这5类主题的星级进行评分,如8311篇被分为“一般”的点评文档对应3颗星,即均为为3分。一个服务设施的评价文档是多样的,我们只需计算其全部点评文档的算术平均值,即可获得该设施的平均满意度。更细致地,我们可以根据时间段来计算某些设施的分值以了解该设施满意度的变化及规律,更重要的,通过获得一个区域内某时段中特定类型服务设施的满意值,便可以获得评价区域内某类型设施的整体评价。
4.实验结果讨论
我们对所有数据基于LSI主题分类进行了类型判别,以此为每篇点评文档根据其语义赋予不同分值,通过计算这10类数据的算术平均值,获得了北京大上地区域10年间的十大类服务设施现状满意度变化。图 26展示了大上地地区10类型服务设施随时间(2012-12月至2013年12月)而发生的变化,可以看出大上地地区的各类服务设施评价在2.5-4之间,但整体轴线在3.5左右,即高于一般水平。
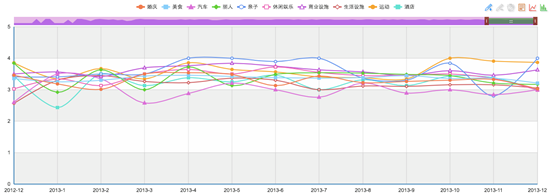
图 26 服务设施满意度时序变化(2012.11-2013.11)
在大上地区域规划方案制定前,规划研究机构通过问卷调查方式发放了500份问卷,最终收回437份有效问卷,问卷有效率达87.40%。问卷涉及公共设施居民满意度的调查部分涉及日常生活10大类服务。
传统问卷调查表数据结果经过整理计算后可以得到这些设施的平均评分值,这些值是调查时刻的用户满意度;由于从点评类SNS数据获得的评价值可以按年或月进行统计计算,为保持数据时效性,我们选择的是2013年11月份的平均评分值,值比较如表 12所示,除酒店类设施传统调查问卷不能提供外,基于SNS数据的调查评分方法提供了与传统方法接近的结果。
|
POI类型 |
婚庆 |
酒店 |
美容美发 |
美食 |
亲子服务 |
汽车服务 |
商业设施 |
生活设施 |
休闲设施 |
运动设施 |
|
传统评分 |
3.42 |
无 |
3.36 |
3.55 |
3.72 |
3.21 |
3.83 |
3.11 |
3.09 |
4.01 |
|
SNS评分 |
3.02 |
3 |
3.16 |
3.31 |
4 |
3 |
3.62 |
3.05 |
2.98 |
3.86 |
对上表中的两组数据进行了显著性差异分析,其p-level值为0.58907,远大于检验样本的显著性差异p值0.05,即两组数没有显著性差异。
除此以外,基于SNS评价数据的方法还具有传统方法无法实现的空间服务设施满意度调查功能,在图 27中展示了大上地区域的美食类服务设施满意度的空间分布(核密度图),其颜色越深表示满意度越高,这些最满意的美食类服务分属两大类区域,一是建筑年代较轻的大上地核心区域,另一个是城中村区域,而其它部分的服务满意度居于较低水平。
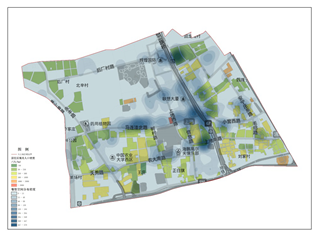
Fig.5 The Satisfaction of Space Distribution of delicacy services
5. 总结
本文基于点评文档数据对大上地地区的上一个规划成果进行了评价与分析,并与新一轮规划的问卷样本进行了比对,结果表明通过点评类SNS数据进行的城市规划实施成果定量评估结果与传统问卷调查接近,且能够提供具有时序和空间特征的数据结果,具有较高的实用性与可行性。随着SNS应用数据的愈加丰富,它将能够中更多领域的评价及预测中发挥作用,下一步我们将选择更多的大数据源来为城市规划定量评估提供更加广泛可靠的评价依据,以此推进城市规划的定量化。
参考文献
[1] Oliveira V, Pinho P. Evaluation in urban planning: Advances and prospects[J]. Journal of Planning Literature, 2010,24(4):343-361.
[2] Berke P, Backhurst M, Day M, et al. What makes plan implementation successful? An evaluation of local plans and implementation practices in New Zealand[J]. Environment and Planning B:Planning and Design, 2006,33(4):581-600.
[3] Poplin A. Playful public participation in urban planning: A case study for online serious games[J]. Computers, Environment and Urban Systems, 2012,36(3):195-206.
[4] Kingston R, Carver S, Evans A, et al. Web-based public participation geographical information systems: an aid to local environmental decision-making[J]. Computers, Environment and Urban Systems, 2000,24(2):109-125.
[5] Wang S J, Middleton B, Prosser L A, et al. A cost-benefit analysis of electronic medical records in primary care[J]. The American journal of medicine, 2003,114(5):397-403.
[6] Prestwich A, Lawton R, Conner M. The use of implementation intentions and the decision balance sheet in promoting exercise behaviour[J]. Psychology and Health, 2003,18(6):707-721.
[7] Alexander E R, A. F. Planning and plan implementation - notes on evaluation criteria[J]. Environment and Planning B: Planning & Design, 1989,2(16):127-140.
[8] Sager T. The family of goals-achievement matrix methods: respectable enough for citizen participation in planning?[J]. Environment and Planning A, 1981,13(9):1151-1161.
[9] Shiwen Sun, Yu Zhou.Evaluation Research on Urban Planning Implementation[J].Urban Planning Forum, 2003,2(02):15-20. (孙施文, 周宇. 城市规划实施评价的理论与方法[J]. 城市规划汇刊, 2003,2(02):15-20.)
[10] Fei Dai, Jun-hua Zhang.The Survey Methods in Planning and Design 1——Questionnaire Survey(Theory Part)[J].Chinese Landscape Architecture, 2008,10(10):82-87. (戴菲, 章俊华. 规划设计学中的调查方法(1)——问卷调查法(理论篇)[J]. 中国园林, 2008,10(10):82-87.)
[11] DeAndrea D C. Participatory social media and the evaluation of online behavior[J]. Human Communication Research, 2012,38(4):510-528.
[12] Hicks A, Comp S, Horovitz J, et al. Why people use Yelp. com: An exploration of uses and gratifications[J]. Computers in Human Behavior, 2012,28(6):2274-2279.
[13] Sui D, Goodchild M. The convergence of GIS and social media: challenges for GIScience[J]. International Journal of Geographical Information Science, 2011,ahead-of-p(ahead-of-p):1-12.
[14] Chen M, Lin H, He L, et al. Real-geographic-scenario-based virtual social environments: integrating geography with social research[J]. Environment and Planning B: Planning and Design, 2013,40(6):1103-1121.
[15] Chang Z E, Li S. Geo‐Social Model: A Conceptual Framework for Real‐time Geocollaboration[J]. Transactions in GIS, 2012,17(2):182-205.
[16] Deerwester S C, Dumais S T, Landauer T K, et al. Indexing by latent semantic analysis[J]. Journal of the American Society for Information Science and Technology, 1990,41(6):391-407.
[17] Xu L, Zhang Q, Wang D D, et al. Research of Chinese Segmentation Based on MMSeg and Double Array TRIE[J]. Advanced Materials Research, 2011,225:945-948.
[18] Zhang W, Yoshida T, Tang X. A comparative study of TF* IDF, LSI and multi-words for text classification[J]. Expert Systems with Applications, 2011,38(3):2758-2765.
上一篇:面向网页文本的地理要素变化发现
